The following package(s) will be installed:
- eurostat [4.0.0]
These packages will be installed into "/__w/r-introduction/r-introduction/renv/library/linux-ubuntu-noble/R-4.5/x86_64-pc-linux-gnu".
# Installing packages --------------------------------------------------------
- Installing eurostat 4.0.0 ... OK [linked from cache]
Successfully installed 1 package in 5.9 milliseconds.Introduction to quantitative methods with
Chapter 2: Manipulating structured data
Introductory chapter
Note
- Exercises associated with this chapter here

The answer: the tidyverse!
The tidyverse ecosystem
readr
- The package for reading flat files (
.csv,.txt…) - Allows obtaining a
tibble, the augmented dataframe of thetidyverse
dplyr
- The central package of the data manipulation ecosystem;
- Data manipulation and descriptive statistics;
dplyr
Aggregated statistics
- split-apply-combine logic with
groupby
Illustration of split-apply-combine
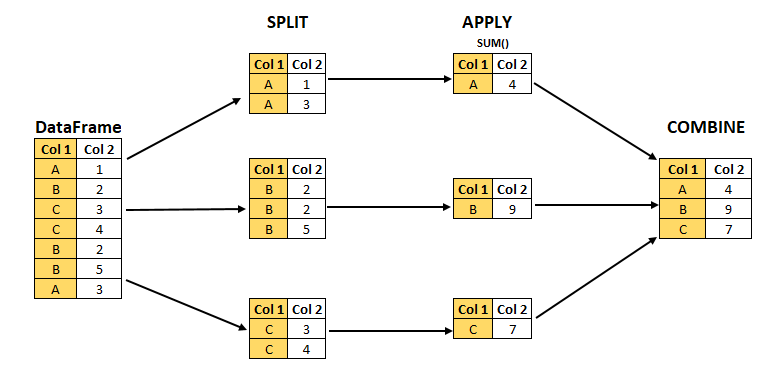
library(dplyr)
pop_by_age %>%
1 as_tibble() %>%
2 filter(TIME_PERIOD == "2025-01-01") %>%
3 group_by(geo) %>%
4 summarise(pop_by_country_2025 = sum(values, na.rm = TRUE))- 1
-
We convert the standard dataframe to
tibble - 2
-
We keep only gas stations (values
2025-01-01ofTIME_PERIOD) - 3
-
We define
geoas a stratification variable to define groups - 4
- We summarize the data by summing gas stations in each group
ggplot
- The essential package for making graphics ❤️;
- Coherent and flexible approach based on the grammar of graphics
- Subject of a dedicated chapter
stringr, forcats and lubridate
![]()
![]()
![]()
- Many functions facilitating manipulation:
- Textual data:
stringr - Categorical data:
forcats - Temporal data:
lubridate
- Textual data:
The magrittr pipe (%>%)
A way to chain operations